
스파르타 코딩클럽 4주차는 날짜로 치면 벌써 3주전에 완료했다. 그럼에도 개발일지 포스팅이 상당히 늦어졌다. 이유는 flask를 이용해 서버와 데이터를 왔다갔다 교환하는 방법이 이해는 되는데, 정리하기가 어려워서 그랬다.
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})데이터베이스에서 데이터 읽고 쓸때 닳도록 사용하는 코드들. 계속 복사 붙여넣기하면서 이번주 요긴하게 사용했다.
프로젝트 1 : 화성땅 공동구매

POST : 데이터베이스에 집어넣기

GET : 서버에서 데이터 가져오기

결과물


프로젝트 2 : 스파르타 피디아
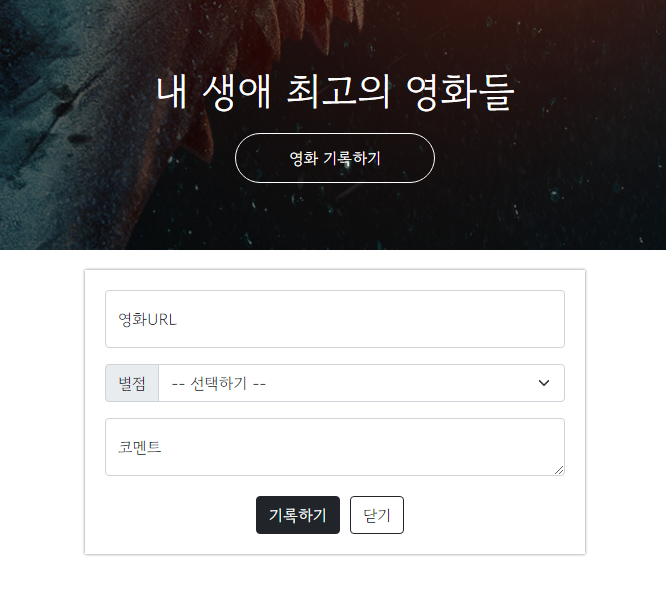
데이터 크롤링 : 메타데이터 가져오기
import requests
from bs4 import BeautifulSoup
url = 'https://movie.naver.com/movie/bi/mi/basic.naver?code=191597'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('meta[property="og:title"]')['content']
image = soup.select_one('meta[property="og:image"]')['content']
disc = soup.select_one('meta[property="og:description"]')['content']
print(title, image, disc)네이버 영화 (https://movie.naver.com/movie/bi/mi/basic.naver?code=191597)의 url로부터 beautifulsoup를 이용해 메타데이터를 가져온다.

메타데이터는 페이지를 <검사> 한 뒤 <head>안에 적혀있는 것을 확인 할 수 있다. 위의 코드는 <head>안의 meta property="og:image"의 content를 가져온 것이다. 코드는 그냥 외우자.
POST : 크롤링한 데이터를 서버에 업로드


GET + 결과물

GET을 사용하는 방법은 동일하다. 영화 기록하기에 네이버 영화의 url을 넣으면 url에서 영화 포스터, 제목, 설명을 크롤링해온다. 다음으로 별점과 코멘트를 기록한다. 크롤링한 데이터와 별점, 코멘트를 모두 서버에 저장한뒤, GET을 통해 가져와 최종적으로 HTML 형태로 사이트에 내보낸다.
마치며
4주차의 프로젝트들은 데이터를 다루는 python과 사이트의 모양과 input을 다루는 html / javascript를 동시에 사용하는 부분이 복잡했다. 이부분은 역시 한번에 써먹기는 어려울 것 같다. 강의를 듣고 따라하는 것 자체는 어렵지 않았지만 이해하고 정리하는데 꽤 오랜 시간이 걸렸다. 개발일지 작성이 미루어진 이유도 정리가 여간 귀찮은일이 아니었기 때문이다. 그래도 늦게나마 개발일지를 통해 정리하니 확실히 정리가 된 느낌이다.
이쯤 배우니 나만의 프로젝트를 만들고자 하는 욕심이 솟는다. 5주차는 AWS를 사용하여 그동안 내 컴퓨터에서만 돌아가는 서버를 24시간 돌릴 수 있게 만든다. 그 때 배운 내용은 다음글에 작성해야겠다.




